with Incremental Geometry Priors
Stream3D-VLM is an online 3D vision-language model that supports real-time spatial understanding and interaction directly from streaming video. By incrementally integrating geometry priors and employing geometry-adaptive voxel compression, our approach enables efficient and continuous 3D scene comprehension without requiring offline processing or complete scene observations.
Despite advances in 3D scene understanding, existing 3D Large Multimodal Models operate in offline settings, requiring complete scene observations or predefined video clips. In this paper, we present an online 3D vision-language model that enables real-time spatial understanding from streaming video. Our approach adopts an autoregressive streaming control modeling based on the LLM's next-token prediction objective to learn when to respond, and employs a lightweight Visual-Spatial Feature Integration (VSFI) module to incrementally inject temporally aligned geometry priors into the visual stream. To alleviate long-context decoding overhead, we propose a plug-and-play Geometry-Adaptive Voxel Compression (GAVC) module for efficient visual token compression. To address the scarcity of streaming 3D–language data, we further develop a scalable data generation pipeline that curates over 1M online spatio-temporal 3D QA pairs and establish a comprehensive benchmark spanning 29 tasks. Extensive experiments show that our approach significantly outperforms both proprietary and open-source models across online and offline 3D spatial understanding, reasoning, and grounding tasks.
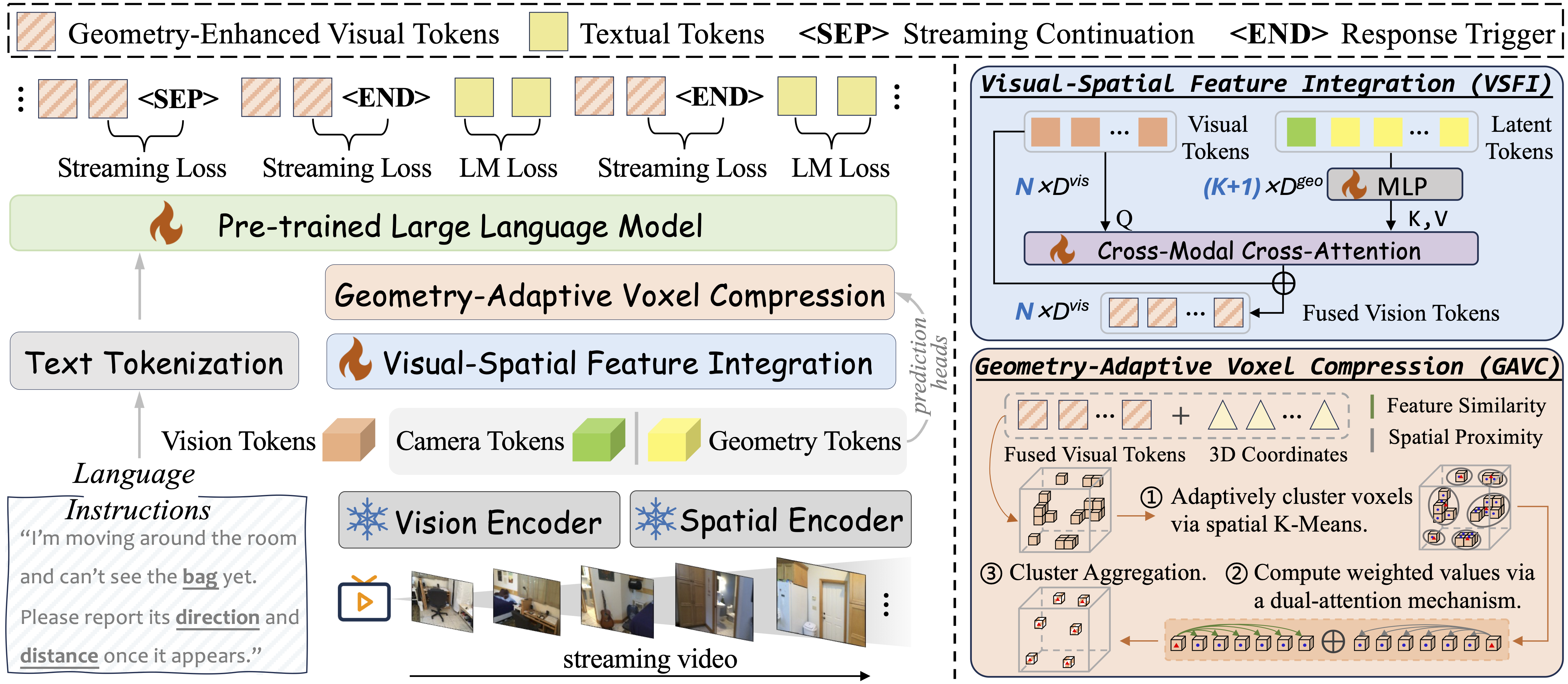
Overview of our proposed Stream3D-VLM. Our pipeline processes streaming video as a temporally ordered input sequence. We utilize the LLM’s native next-token prediction to jointly optimize a streaming control loss and the standard language modeling (LM) loss, enabling the model to learn when to respond or keep silent. We then suggest the VSFI module to inject temporally aligned geometric priors from a 3D reconstruction model into the visual stream. To mitigate long-context redundancy in online inference, we further propose a plug-and-play GAVC module that dynamically compresses visual tokens guided by 3D structure, enabling real-time deployment.
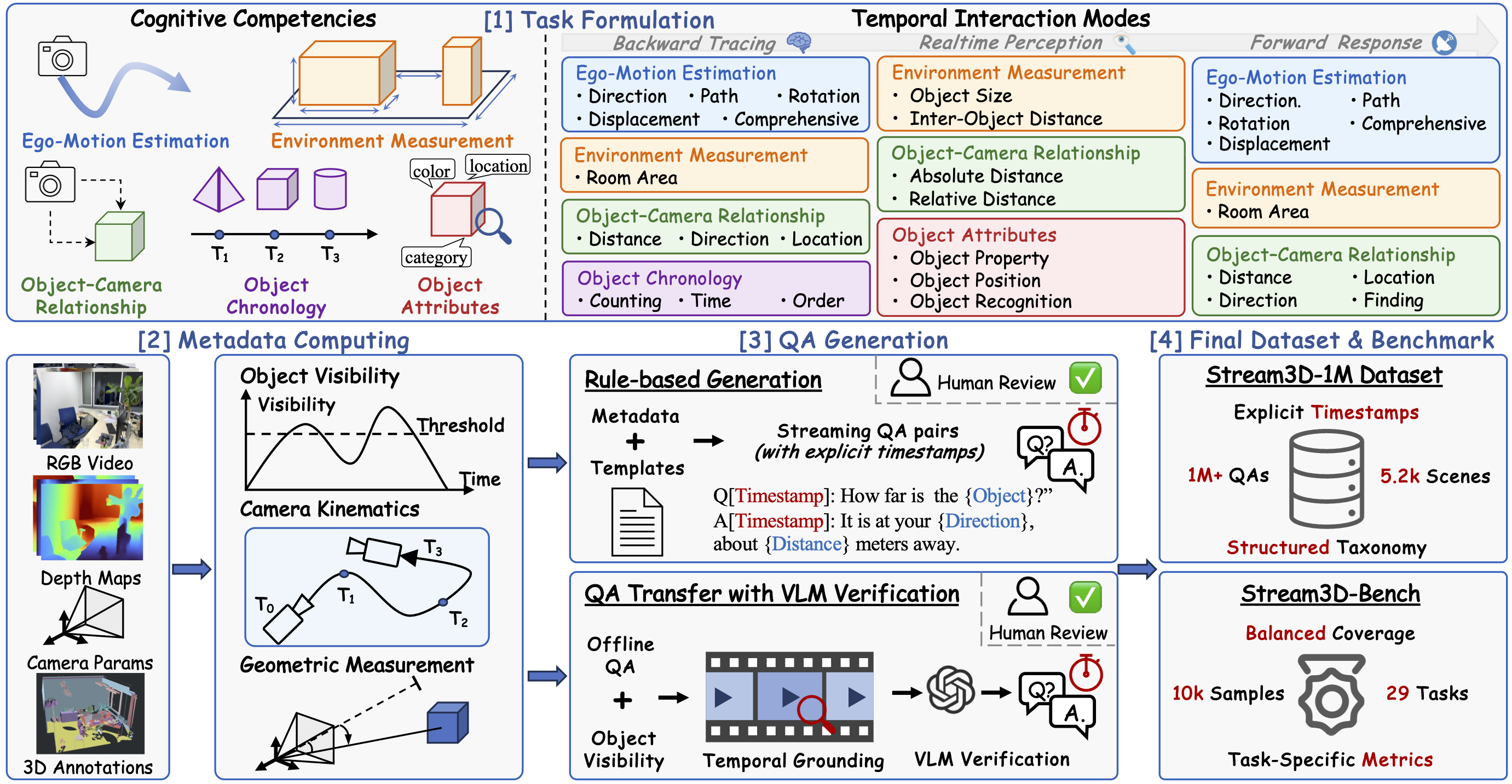
Illustration of our data generation pipeline. Guided by a comprehensive task taxonomy spanning five cognitive competencies and three temporal interaction modes, the pipeline leverages detailed metadata from RGB-D video streams and a hybrid generation strategy to construct a large-scale spatio-temporal 3D QA dataset and the Stream3D-Bench for evaluating online 3D spatial understanding.
Our benchmark spans 5 cognitive competencies across 3 temporal interaction modes, covering diverse spatio-temporal 3D understanding tasks.
🔍 Tasks that require recalling and reasoning about past observations from the video stream.
🔍 Tasks that require understanding the current frame and immediate surroundings.
🔍 Tasks that require monitoring future events in the stream.
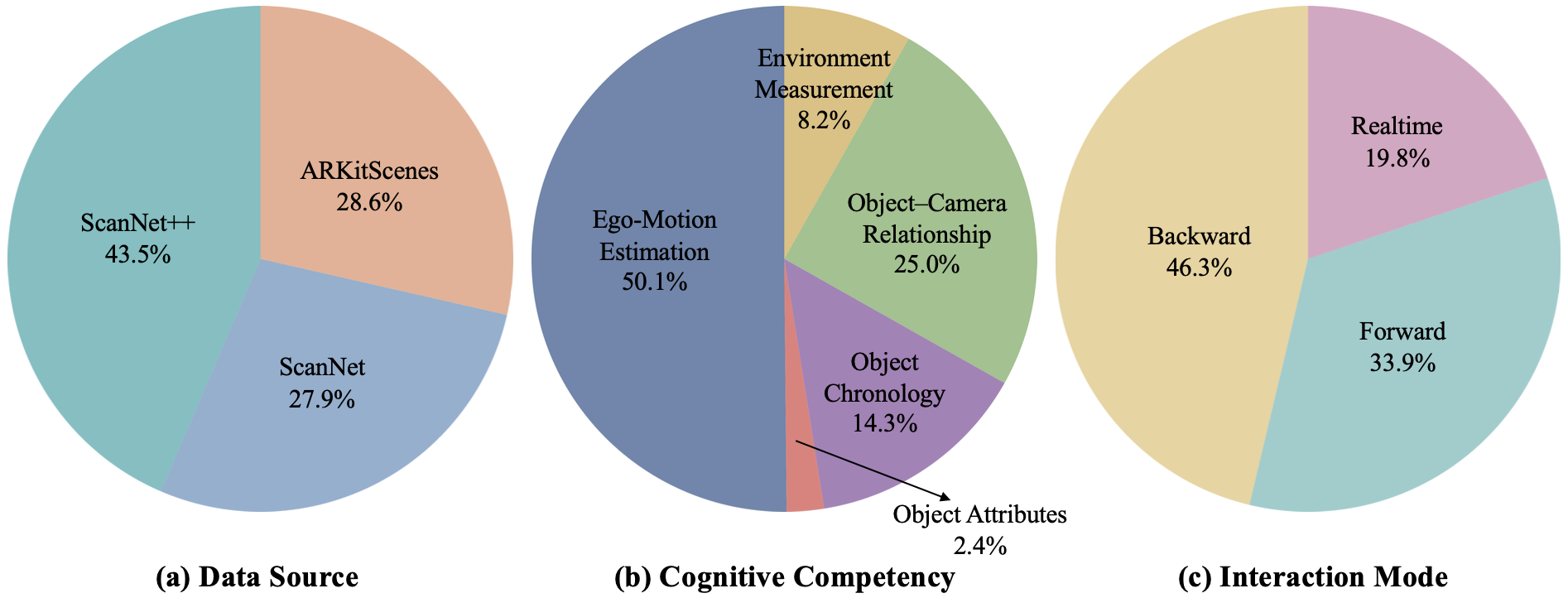
Statistical Distribution of Stream3D-1M Dataset. The figure visualizes the composition of the training set (over 1M samples) across three key dimensions: (a) Data Source, highlighting that ScanNet++ contributes the plurality of QA pairs (43.5%) due to its dense annotations; (b) Task Category, dominated by Camera Motion tasks (50.1%) which serve as the foundation for spatial tracking; and (c) Interaction Mode, demonstrating a strong emphasis on long-term memory (Backward, 46.3%) and active monitoring (Forward, 33.9%).
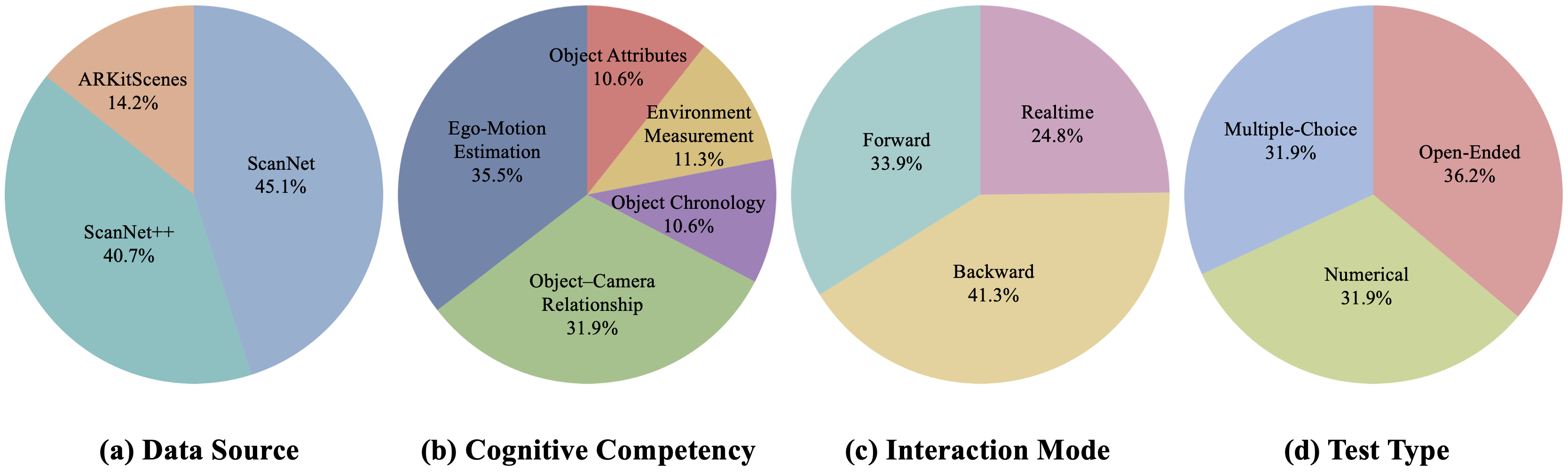
Statistical Distribution of Stream3D-Bench. The four pie charts illustrate the composition of the benchmark across diverse dimensions: (a) Data Source, showing a robust integration of ScanNet, ScanNet++, and ARKitScenes; (b) Task Category, covering five core cognitive capabilities; (c) Interaction Mode, balancing tasks across Memory (Backward), Observation (Realtime), and Monitoring (Forward) phases; and (d) Answer Type, maintaining a uniform distribution among Open-ended, Numerical, and Multiple-choice formats.
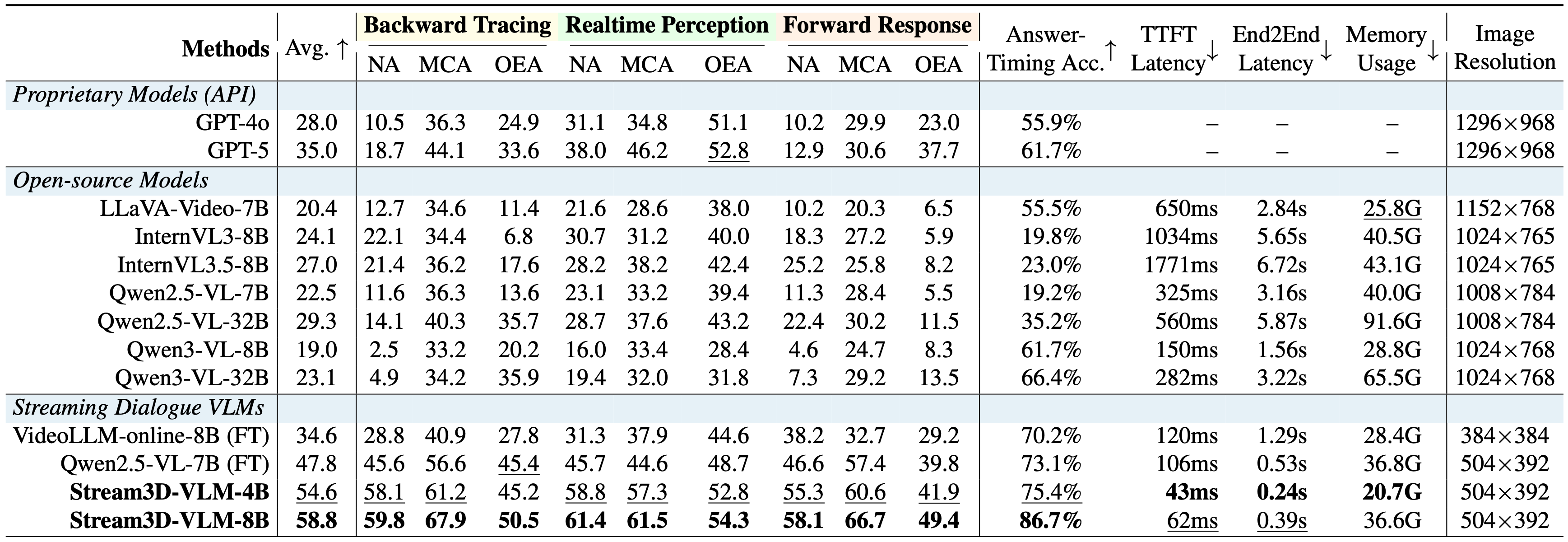
Evaluation results on Stream3D-Bench. Stream3D-VLM consistently outperforms all competing models, delivering the most accurate response timing and the lowest inference latency. NA/MCA/OEA denote numerical, multiple-choice, and open-ended answers, respectively. FT indicates that the model is fine-tuned on our curated online 3D spatio-temporal QA dataset for fair comparison. Bold and underlined values indicate the best and the second-best results, respectively. The results are reported under a 1fps streaming video setting.
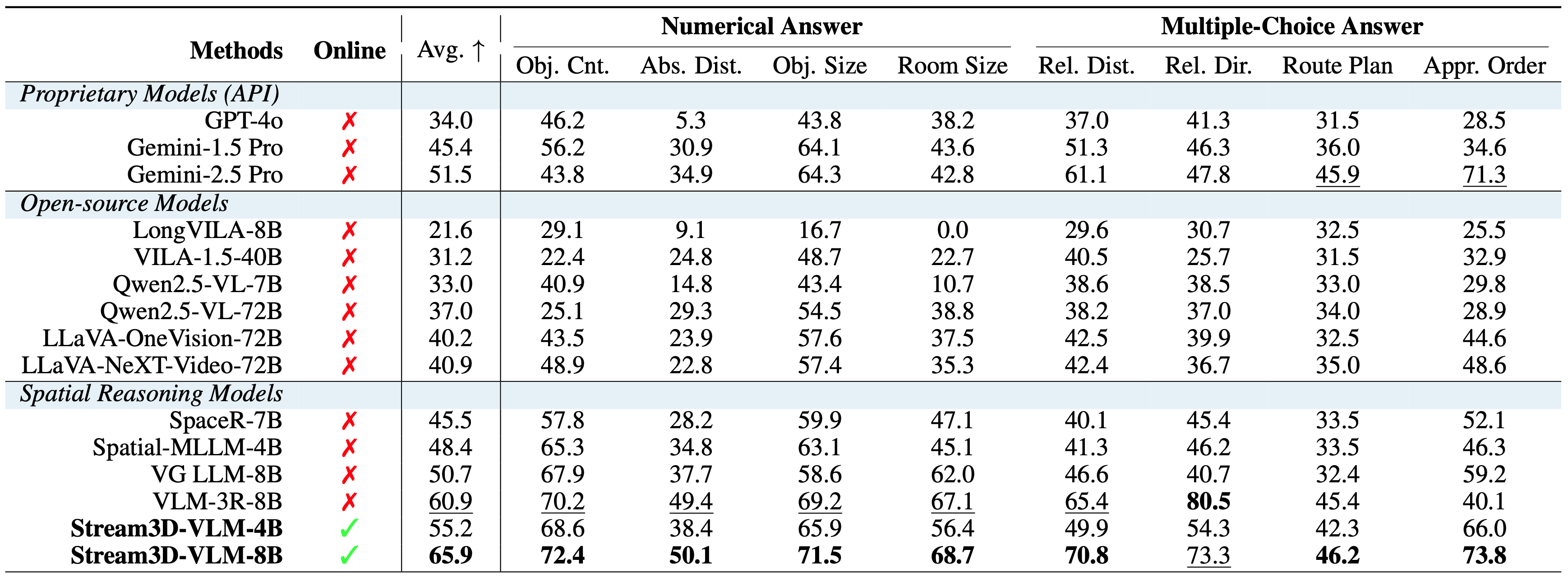
Evaluation results on VSI-Bench. Despite being designed for streaming scenarios, Stream3D-VLM also performs well across all subtasks of the offline spatial perception and reasoning benchmark, significantly surpassing both commercial and open-source models.
@article{yu2026stream3d,
title={Stream3D-VLM: Online 3D Spatial Understanding with Incremental Geometry Priors},
author={Hanxun Yu and Xuan Qu and Lei Ke and Boqiang Zhang and Yuxin Wang and Jianke Zhu and Dong Yu},
journal={arXiv preprint arXiv:2606.06891},
year={2026}
}If you find our work useful in your research, please consider citing our paper and giving us a ⭐ on GitHub. Thank you!